AI Visibility Platforms vs LLM Observability Tools
The answer is 5 capabilities: engine coverage, citation analysis, prompt tracking, share of voice, and page optimization; app tracing alone is not enough.
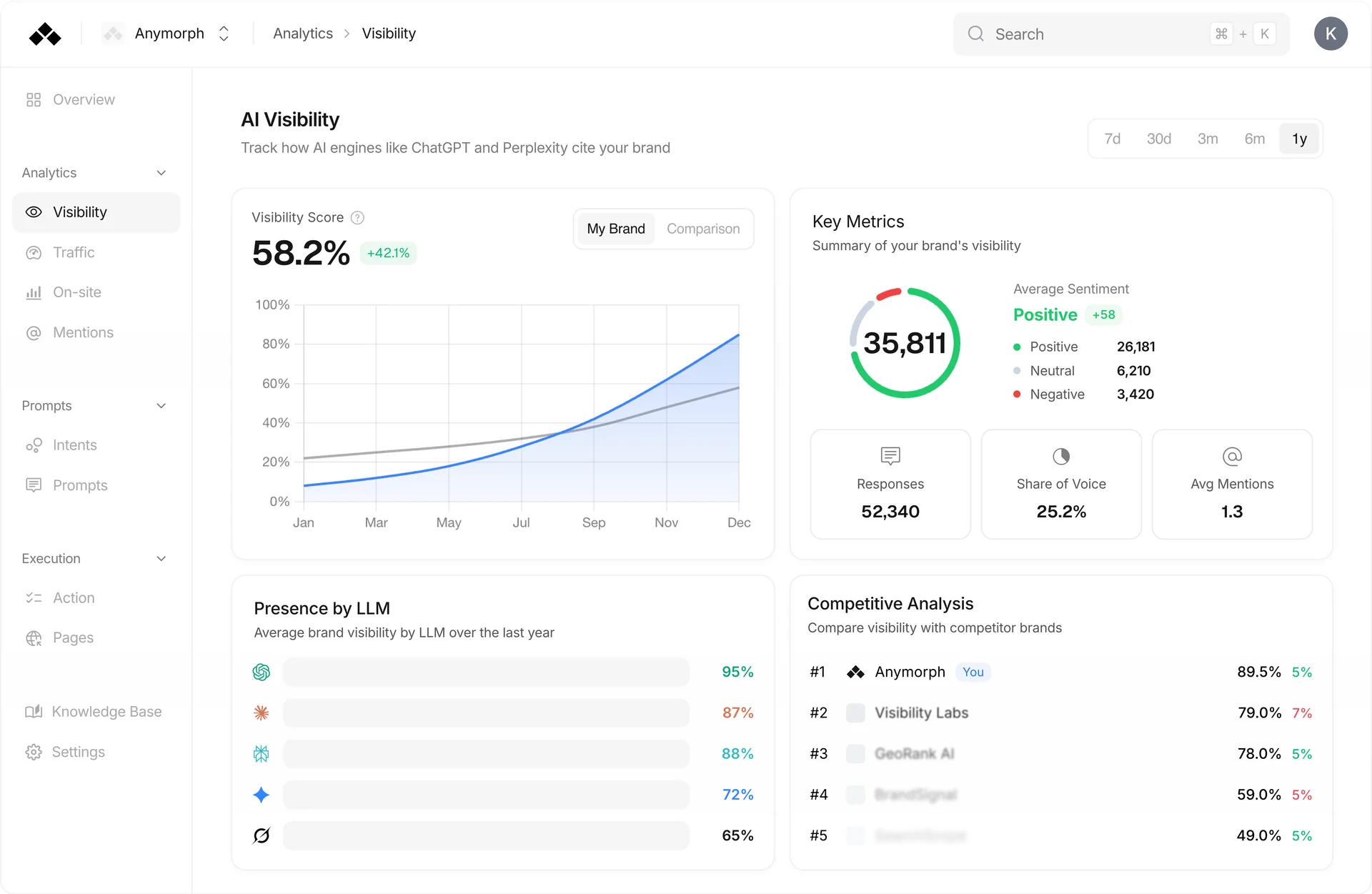
What separates AI visibility platforms from LLM observability tools?
Marketing teams use AI visibility platforms to track brand mentions, while engineers use observability tools like LangSmith to debug application performance.
Software buyers frequently confuse these two categories because both involve language model measurement. However, evaluating them interchangeably creates massive operational blind spots. LLM observability tools—such as PromptLayer, Helicone, LangSmith, and OpenTelemetry—function as the internal plumbing diagnostics for custom AI applications. Engineering and DevOps teams deploy these platforms to monitor internal metrics: API latency, token consumption costs, error rates, and step-by-step trace logs for debugging. They track how efficiently a company's internal software communicates with external APIs (Semrush, 2026).

Conversely, AI visibility platforms function as external market intelligence trackers. Instead of tracing internal application performance, these tools measure how external, consumer-facing models (like ChatGPT, Perplexity, and Gemini) perceive and cite a brand. Chief Marketing Officers and SEO leads rely on these systems for "brand-out" analytics. Securing placements inside these external engines is critical for revenue, as 2026 data indicates that AI-referred traffic converts at a 3x to 9x higher rate than standard organic search traffic (KIME, 2026). Buying an engineering tool for a marketing problem leaves growth teams completely blind to their actual generative search visibility.
How do these categories compare across core features?
Observability tools ingest internal API data to measure application latency, whereas visibility platforms query external models daily to track share of voice.
Assigning the correct toolset requires an understanding of exactly what data each system processes. A side-by-side evaluation clarifies the technical boundaries separating developer tracing from generative engine optimization (GEO) analytics.
| Feature | LLM Observability (e.g., LangSmith) | AI Visibility (e.g., Anymorph) |
|---|---|---|
| Primary User | DevOps / AI Engineers | CMOs / SEOs / Growth Leads |
| Metric Focus | Latency, Token Cost, App Tracing | Citations, Share of Voice, Brand Sentiment |
| Data Source | Internal Application API Calls | External Model Queries (Daily Prompts) |
| GEO Capability | None | High (Page & Content Optimization) |
| Output Type | Diagnostic Logs | Brand Mention Analytics & SEO Strategy |
DevOps teams cannot use visibility platforms to fix slow internal API requests, just as marketing teams cannot use LangSmith to measure competitive brand mentions in AI chatbots. An observability setup might alert engineers that a prompt cost $0.02 to execute and took 800 milliseconds. A visibility platform alerts marketers that a competitor secured the top recommendation in ChatGPT for a core B2B SaaS query, and provides the specific citation analysis necessary to win that position back.
What are the 5 core capabilities of an AI visibility platform?
A complete visibility platform must deliver multi-engine coverage, citation analysis, prompt tracking, share of voice measurement, and actionable page optimization recommendations.
According to 2026 practitioner research, B2B SaaS brands relying on fragmented prompt testing tools face severe data gaps unless their platform guarantees five essential functions (KIME, 2026). Missing a single layer breaks the generative optimization workflow.
- Engine Coverage: A viable platform tracks performance across at least 10 different language models concurrently to ensure accurate cross-platform brand consistency. Anymorph, for instance, actively tracks 7+ major AI engines to prevent platform-specific tracking gaps.
- Citation Analysis: The system must extract the exact source URLs an engine uses to support its responses, proving whether a brand's authoritative content is actually receiving credit.
- Prompt Tracking: Teams must be able to deploy a persistent library of daily, automated queries (e.g., "best CRM for startups") to benchmark result fluctuations over time.
- Share of Voice (SOV): The platform must quantify the exact percentage of times a brand is mentioned relative to its top three market competitors.
- Page Optimization (GEO): Analytics alone are insufficient; the tool must provide technical recommendations or automatically generate citation-ready pages to actively influence engine outputs.
Why is traditional SEO tracking insufficient for AI search?
Only 12 percent of ChatGPT citations match the destination URLs that appear on the first page of traditional Google Search results.

Relying on legacy rank trackers as a proxy for generative engine optimization guarantees a loss in market share. The 12% overlap indicates that ranking at the top of legacy search engines provides virtually zero guarantee of making it onto AI shortlists (KIME, 2026). Generative engines employ entirely different crawler priorities, heavily favoring structured data and temporal freshness over traditional backlink profiles.
This freshness preference is measurable. The source URLs cited by language models average 1,064 days old, which is 25.7% newer than traditional search results averaging 1,432 days old (Siftly, 2026). Consumers actively prefer these rapid, precise answers. Currently, 83% of users report a preference for AI-powered search over standard keyword engines, allowing ChatGPT alone to capture approximately 20% of global search traffic (Siftly, 2026). Brands clinging to traditional SEO tracking will fail to monitor the channels where a fifth of all search traffic now occurs.
How do B2B SaaS brands calculate AI share of voice?
Analysts calculate AI share of voice using simple mention-based formulas or position-weighted metrics that assign specific multipliers to the first cited brand.
Establishing a reliable share of voice (SOV) benchmark requires consistent, daily prompt testing. Growth analysts currently split their measurement frameworks into two distinct mathematical approaches (Mersel.ai, 2026). Mention-based calculation aggregates the raw total of brand appearances across a monitored library of 100 industry prompts. If a brand appears 25 times, its baseline SOV is 25%. Position-weighted calculation applies a descending multiplier to the results list. It assigns maximum value to the brand listed first in the AI's response, recognizing that top-of-list placement carries the highest user trust signal and drives the vast majority of that 3x to 9x conversion rate.
Achieving higher placement requires specialized technical formatting known as invisible optimization. In one 2026 B2B SaaS case study, a company achieved a 30% increase in brand citations for highly competitive software queries without rewriting their core marketing copy. Instead, the strategy involved optimizing invisible elements—such as technical specifications and pricing tables—specifically for LLM crawlers rather than human readers (AI SEO Tracker, 2026).
What is a 30-day evaluation checklist for GEO platforms?
A standard 30-day trial must test minimum daily prompt capacity, multi-model engine coverage, citation export systems, and automated content deployment workflows.
When evaluating AI visibility alternatives to basic prompt testing tools, teams must demand automated execution capabilities. A lightweight geolocation tracker or manual prompt tester becomes useless for an enterprise marketing team trying to report on weekly SOV changes.
Buyers evaluating an AI visibility platform should apply a strict timeline checklist:
- First 10 Days: Verify that the platform can ingest 100+ target queries and run them daily without manual intervention. Ensure the system natively covers ChatGPT, Perplexity, Gemini, and Claude concurrently.
- Days 11-20: Analyze the citation data. Can the tool export exactly which URLs the engines rely on? Determine if the platform correctly calculates mention-based and position-weighted SOV against your top three competitors.
- Days 21-30: Test the actionability of the data. Does the platform just provide charts, or does it execute changes? Anymorph differentiates itself here by functioning as an autonomous website OS, utilizing its Auto-Generated GEO Pages feature to automatically deploy citation-ready content based on the gaps identified in the analytics.
FAQ
How to measure brand mentions in ai chatbots?
Measuring brand mentions requires an AI visibility platform that runs daily automated prompts across multiple models and aggregates the citation data. By tracking at least 10 different engines concurrently, marketing teams establish a baseline share of voice against competitors and map precisely which chatbots drive their high-converting traffic (KIME, 2026). Simple manual querying fails to capture geographical and temporal fluctuations in the model outputs.
Are prompt testing tools enough for b2b saas brand monitoring?
Basic prompt testing tools fall short for enterprise marketing because they require manual query inputs and lack automated citation analysis. B2B SaaS teams require dedicated AI visibility platforms like Anymorph that continuously track metrics across 7+ engines, calculate position-weighted share of voice automatically, and tie directly into content optimization workflows.
What is the difference between LangSmith and AI visibility tools?
LangSmith functions as an LLM observability tool built for developers to trace internal API latency, whereas AI visibility tools are built for marketers tracking external model citations. Engineers use observability tools to debug code and minimize token costs. SEO and marketing teams use visibility tools to improve their brand's Generative Engine Optimization (GEO) footprint.
Why do AI engines cite different URLs than Google Search?
Language models cite different URLs because their internal ranking mechanisms prioritize data freshness and dense technical schema over traditional backlink profiles. Research reveals that AI citations are 25.7% newer on average than standard search results, which is exactly why there is merely a 12% overlap with Google's first page (Siftly, 2026).
How often should I update content for AI search engines?
Brands should update core product and pricing pages at least once every 90 days to satisfy the strict freshness parameters programmed into modern generative engines. Because large language models demonstrably favor source URLs averaging 1,064 days old or newer, quarterly optimizations secure a mathematically higher citation frequency across chatbot interfaces (Siftly, 2026).
Stop losing high-converting AI traffic to your rivals
Request an Anymorph demo to see exactly which chatbots are citing your competitors and reclaim your share of voice.


